

Los modelos de lenguaje de inteligencia artificial (en inglés large language models, LLMs) son algoritmos complejos basados en redes neuronales, diseñados para procesar y generar lenguaje humano de forma coherente.
- En el desarrollo de un software, un algoritmo es un “conjunto ordenado y finito de operaciones” que permite la solución de un problema.
Estos sistemas se entrenan con un gran volumen de datos de texto y pueden responder a preguntas y mantener conversaciones con los usuarios.
Los LLMs descomponen el lenguaje en patrones complejos, lo convierten en representaciones numéricas y generan respuestas basadas en probabilidades, utilizando redes neuronales que procesan la información en base a su entrenamiento.
- En este artículo exploramos cómo funciona el proceso, centrándonos en cuatro conceptos: word embedding, redes neuronales, la probabilidad en la generación de palabras y las alucinaciones de los modelos.
Word Embedding: la traducción de humano a máquina
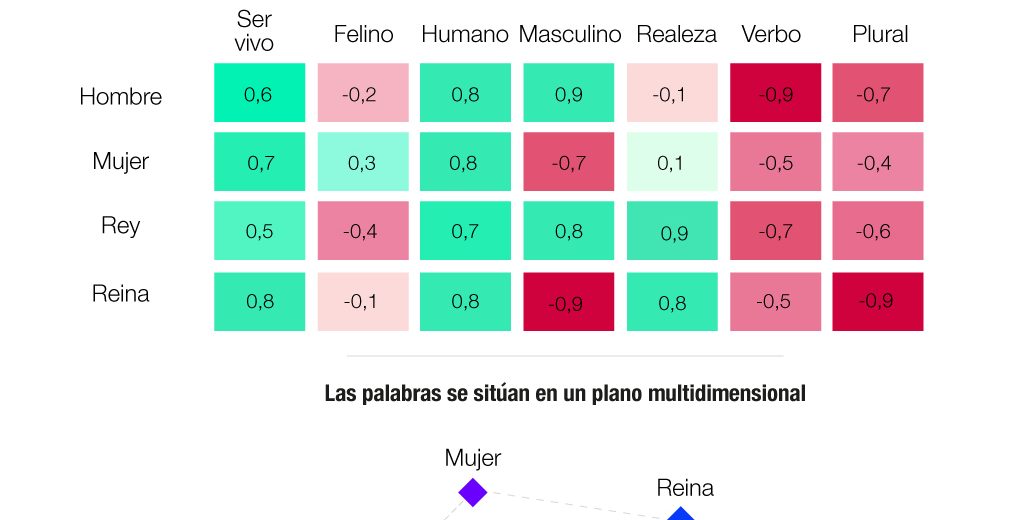
Para que un LLM pueda procesar el lenguaje humano, las palabras deben transformarse en algo que las máquinas puedan manejar: números. Aquí entra el concepto de word embedding, o representación vectorial de palabras.
A partir de un entrenamiento previo, los modelos de lenguaje asignan una serie de valores numéricos a cada palabra del prompt (instrucción) del usuario. Dependiendo del modelo, puede haber cientos o miles de valores que capturan las categorías léxicas y las relaciones de cada palabra con otras.
- Un prompt es la instrucción que se introduce en el sistema de IA para obtener unos resultados específicos. Puede ser una sola frase o varios párrafos, según el Massachusetts Institute of Technology (MIT).
Por ejemplo, en la representación numérica de word embeddings, la palabra “rey” estará más cerca de “reina” que de “coche”, porque comparten significados similares. Lo mismo ocurre cuando el sistema funciona en varios idiomas, la misma palabra en lenguajes distintos tendrá una representación numérica muy similar.
Mediante este proceso, las palabras con significados similares se sitúan cerca unas de otras en este espacio multidimensional. Como explica a Newtral.es Grigory Sapunov, doctor en inteligencia artificial y fundador de la empresa Intento, especializada en IA generativa, “si en dos prompts dices lo mismo pero con palabras diferentes, la posición general de las dos frases estará muy cercana en el espacio de word embedding”.
- Según Aruna Sankaranarayanan, investigadora del Massachusetts Institute of Technology (MIT), el word embedding consiste en “coger el lenguaje y romperlo en unidades pequeñas, denominadas vectores”.

Probabilidad: ¿cómo calculan la siguiente palabra los modelos de lenguaje?
Un aspecto clave de los LLMs es que no “adivinan” qué palabra viene a continuación, sino que generan una distribución de probabilidad para cada palabra posible. Esta se calcula en función de los patrones que el modelo ha aprendido durante su entrenamiento.
Por ejemplo, si la entrada es “el niño”, el modelo generará una lista de palabras que podrían seguir, como “juega”, “está” o “come”, cada una con su propia probabilidad basada en el contexto y en las relaciones entre los valores numéricos asignados a cada palabra en el entrenamiento.
El entrenamiento de los LLMs. ChatGPT, uno de los LLMs más populares, entrenó sus datos a partir de tres fuentes de información, según OpenAI:
- Información pública disponible en internet, excluyendo la que está en la deep web o tras un muro de pago, así como la que incluye discurso de odio o contenido para adultos.
- Información de terceros a la que accede mediante acuerdos empresariales. OpenAI firma convenios con empresas y organizaciones para utilizar sus datos como material de entrenamiento.
- Información generada por usuarios e investigadores. Por defecto, ChatGPT utiliza sus conversaciones para entrenarse y mejorar su contenido. Esta opción puede desactivarse.
Ojo. Como informamos en Newtral.es, ChatGPT ha utilizado en su entrenamiento artículos de medios como The Washington Post, el Financial Times o The New York Times, que presentó una demanda por violación de derechos de autor. El uso de contenido protegido por derechos de autor para entrenar modelos del lenguaje ha sido y sigue siendo objeto de debate.
- ¿De dónde saca las respuestas? Aunque algunos modelos de lenguaje están conectados a internet, según explica Sapunov, la mayoría se apoya más en su entrenamiento que en las funciones de búsqueda. Según el experto, la proporción depende del modelo y de la instrucción del usuario, y es imposible determinar su valor exacto. Pero, por norma general, el entrenamiento es lo que más peso tiene en la respuesta. En cambio, cuando el modelo no está conectado a internet, sus respuestas se limitan a la información recibida durante su entrenamiento.
No todo es ChatGPT. Según declara a Newtral.es Raymond Duch, investigador de la Universidad de Oxford, “nos movemos hacia un escenario con muchos tipos de modelos muy específicos haciendo tareas muy específicas”. Como indica, estamos asistiendo a una “democratización” de los modelos de lenguaje, permitida por la posibilidad de asignar capas de entrenamiento específico a modelos base.
Algunas grandes empresas, como Bloomberg, han desarrollado su propio modelo especializado en tareas específicas, en este caso financieras, pero según Duch “no hace falta ser una gran organización”, y el futuro pasa por los modelos descentralizados construidos por la comunidad de usuarios.
Esta democratización tiene la ventaja de evitar que un grupo reducido de grandes empresas controle el futuro de la inteligencia artificial generativa, pero, según el experto, también plantea potenciales riesgos asociados al mal uso, en planos tan diversos como la desinformación, el hacking o incluso la industria militar o química.
Redes neuronales: el cerebro detrás de los modelos de lenguaje
Los LLMs se basan en redes neuronales, estructuras digitales formadas por varias capas de “neuronas” conectadas entre sí. Cada neurona recibe información, la procesa y la pasa a la siguiente capa, creando un flujo de información hasta que se produce una respuesta.
Durante el entrenamiento, la red neuronal ajusta miles de millones de valores numéricos que determinan cómo cada neurona debe actuar y distribuir la información (output) ante diferentes entradas (input). Estos valores son fundamentales para que el modelo aprenda los fundamentos del lenguaje, como la estructura gramatical o el significado de las palabras.
Según Sapunov, el proceso se podría simplificar así: el modelo recibe una oración, la descompone en sus componentes más pequeños (las palabras, ahora representadas como números gracias a los word embeddings), y luego pasa esos números a través de múltiples capas para procesarlos, según su entrenamiento y el contexto de la conversación, y dar una respuesta.
- ¿Por qué hablamos de cajas negras? En los LLMs se utiliza el término ‘black box’ (caja negra) para referirse a la complejidad de las operaciones que llevan a cabo. Según Sapunov, cuando el modelo calcula la probabilidad de las palabras generadas, “hay miles de millones de números multiplicándose entre sí, y es muy difícil entender lo que está pasando”.
Como afirma Duch, el problema de la trazabilidad (poder reproducir los cálculos hechos por el modelo) viene por la gran dimensión del entrenamiento y de los datos que manejan los modelos, que hace complejo poder reconstruir todas sus operaciones.
Alucinaciones: cuando el modelo inventa información
En el campo de los LLMs, el término ‘alucinación’ se refiere a las ocasiones en las que los modelos de lenguaje no cuentan con el entrenamiento o el acceso a la información necesaria para proporcionar una respuesta y, en lugar de informar de ello al usuario, se la inventan.
Según explica Sapunov, esto era más frecuente en los primeros modelos, y en la actualidad tienen una mayor capacidad de decir que no saben algo. Aun así, en ocasiones, generan una respuesta basada en la información que tienen, aunque sea incorrecta, porque están diseñados para generar texto coherente pero no para verificar su exactitud, indica el experto.
En palabras de Raymond Duch, debido a que el entrenamiento de los modelos de lenguaje es probabilístico, “la posibilidad de error siempre está presente”. Al elegir su siguiente palabra, los modelos presentan un porcentaje de probabilidad de acierto, que depende en gran medida de su entrenamiento, pero que, al menos aún, nunca es del 100%.
- Grigory Sapunov, doctor en inteligencia artificial y fundador de la empresa Intento
- Aruna Sankaranarayanan, investigadora del Massachusetts Institute of Technology (MIT)
- Raymond Duch, investigador de la Universidad de Oxford
- Word Embeddings: A Survey. Felipe Almeida, Geraldo Xexéo
- OpenAI



