ChatGPT ahora deja a los usuarios dar o quitar permisos sobre sus datos. OpenAI ha anunciado esta semana que sus usuarios pueden pedir que los textos que introducen en la plataforma no se usen para entrenamiento de este gran modelo de lenguaje. Además, permite a sus usuarios la descarga del historial de sesiones.
Estas nuevas opciones para permisos aparecen a los usuarios en sus Ajustes bajo “Data Controls” (control de datos). Si se desmarca la opción, las nuevas conversaciones que tenga el usuario con ChatGPT no se utilizarán para el entrenamiento de la inteligencia artificial conversacional, y tampoco aparecerán en la columna izquierda. Antes de borrarlas definitivamente, OpenAI guardará las conversaciones internamente durante 30 días y se reserva el derecho de revisarlas “sólo cuando lo necesite para monitorizar abusos”.
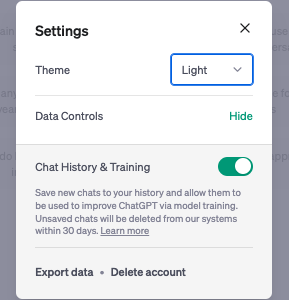
Eso sí, si no quieres ceder los derechos de tus conversaciones a OpenAI, tampoco podrás conservar la lista de archivos de las mismas. OpenAI no ha explicado por qué retira esta función a esos usuarios. Pero sí ha dicho que están trabajando en una suscripción de pago “ChatGPT Business” para “profesionales y empresas que necesitan tener más control sobre sus datos”.
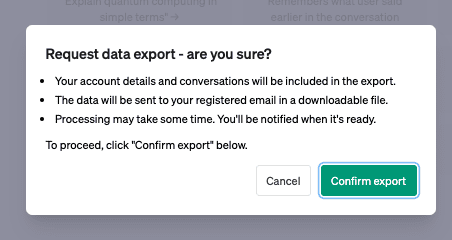
También incorporan una opción de descarga de todos los datos que el usuario ha enviado a ChatGPT, tanto los de registro como las conversaciones. Una vez solicitados, envían al email un enlace con un archivo HTML comprimido y varios archivos tipo JSON que contienen las sesiones de chats con ChatGPT.
Privacidad y permisos en textos usados para entrenar IA
Los grandes modelos de lenguaje como GPT-3 o GPT-4, en los que se basa ChatGPT, son sistemas de inteligencia artificial que usan el aprendizaje automático (machine learning) para entender el lenguaje humano, reproducirlo, traducir textos y otra serie de usos que descubrimos constantemente.
Lo hacen basándose en los patrones que descubren en el material con el que han sido alimentados: inmensas cantidades de texto que existen en la web. En el caso de ChatGPT, ha utilizado GPT-3, un modelo mejorado basado en GPT-2, que fue alimentado según la empresa con buena parte de los textos contenidos en millones de sitios web, entre ellos artículos de decenas de medios periodísticos (sobre los que todo indica que ChatGPT no tenía permisos), la Wikipedia, todos los blogs alojados en Blogger y Wordpress, Reddit y otras fuentes.
Desde su lanzamiento en noviembre de 2022 hasta ahora, ChatGPT mantenía registros de las conversaciones y las usaba para afinar su modelo de lenguaje. Esto ha supuesto un gran riesgo de privacidad, ya que en estas conversaciones los usuarios suelen dar muchos datos personales sin haber dado permisos para que se usaran, lo que ha valido a ChatGPT investigaciones por infracción a la privacidad en la Unión Europea.
De hecho, este tipo de medidas pueden estar relacionadas con la advertencia de Italia contra ChatGPT, que abrió la primera investigación europea contra OpenAI. La autoridad nacional italiana de Protección de Datos, conocida como el Garante, fijó una serie de requerimientos a ChatGPT para operar en suelo italiano, como pedir permisos para los usos de los datos, y el ejercicio de los titulares de los datos a ejercer sus derechos de acceso.
- New ways to manage your data in ChatGPT
- La AEPD investiga a OpenAI por ChatGPT mientras el Comité Europeo de Protección de Datos coordina acciones
- Por qué Italia investiga a ChatGPT por su protección de datos y qué implica para el resto de la UE
- Inteligencia Artificial: cuál es su alimento y por qué tiene sesgos
- ChatGPT, Midjourney y las IA generativas tienen un problema de propiedad intelectual
- Foto de Matheus Bertelli